いわゆる”自炊”において重要アイテムとなる「スキャナー」。
両面を連続でキレイに、スキャンしてOCRで文字認識をした上で検索可能なPDFファイルに変換できて、操作がカンタンでしかも高速・・・ということになると、やはりScanSnap。
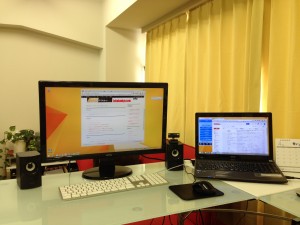
卓上で使うのであれば、超便利な「ScanSnap Cloud」にも対応したiX500がおススメです。
タブレットやスマホで”読書”ができるようにするため、というのが”自炊”する理由の大きな一つなのではありますが、もう一つ、一か所にまとめて保管しておき、文章の中身に至るまで検索可能な状態にしておいて、さらには自分なりのメモ書きも入れておいて、後々活用できるようにしておきたい、という想いの方が、私の場合、強いです。
書籍を検索可能なPDFファイルに変換する
以前、「Windows 10のファイルエクスプローラでPDFファイルを全文検索できるようにする」という記事を書きましたが、こちらの方法を用いれば、PDFファイルをWindows 10の検索機能で全文検索できるようになります。
書籍を資料として活用しようとする場合、棚から取り出して、本そのものを探し出して、ページをめくって目次や索引などを使って目的の記述箇所を探し出すことになります。また、自分で引いた線やメモ書きなどを頼りに探し出すこともあるでしょう。
全文検索ができる状態にしておけば、探し出す手間が大幅に削減できます。
さらに、PDFファイル内で個別にキーワード検索をすることで、即座にそのキーワードが記載されたページにジャンプできます。

文字選択~コピペを可能に
OCR機能により”検索可能なPDFファイル”として保存しておくことで、マウスを使って文字を選択することができるようになり、書籍内の記述の重要箇所をコピー&ペーストすることも可能となります。
マーカーやメモを残せる
紙の本を検索可能なPDFファイルにして”読書”を行った場合、マーカーで線を引いたり、思いついたことなどをメモ書きとして残しておくことができます。
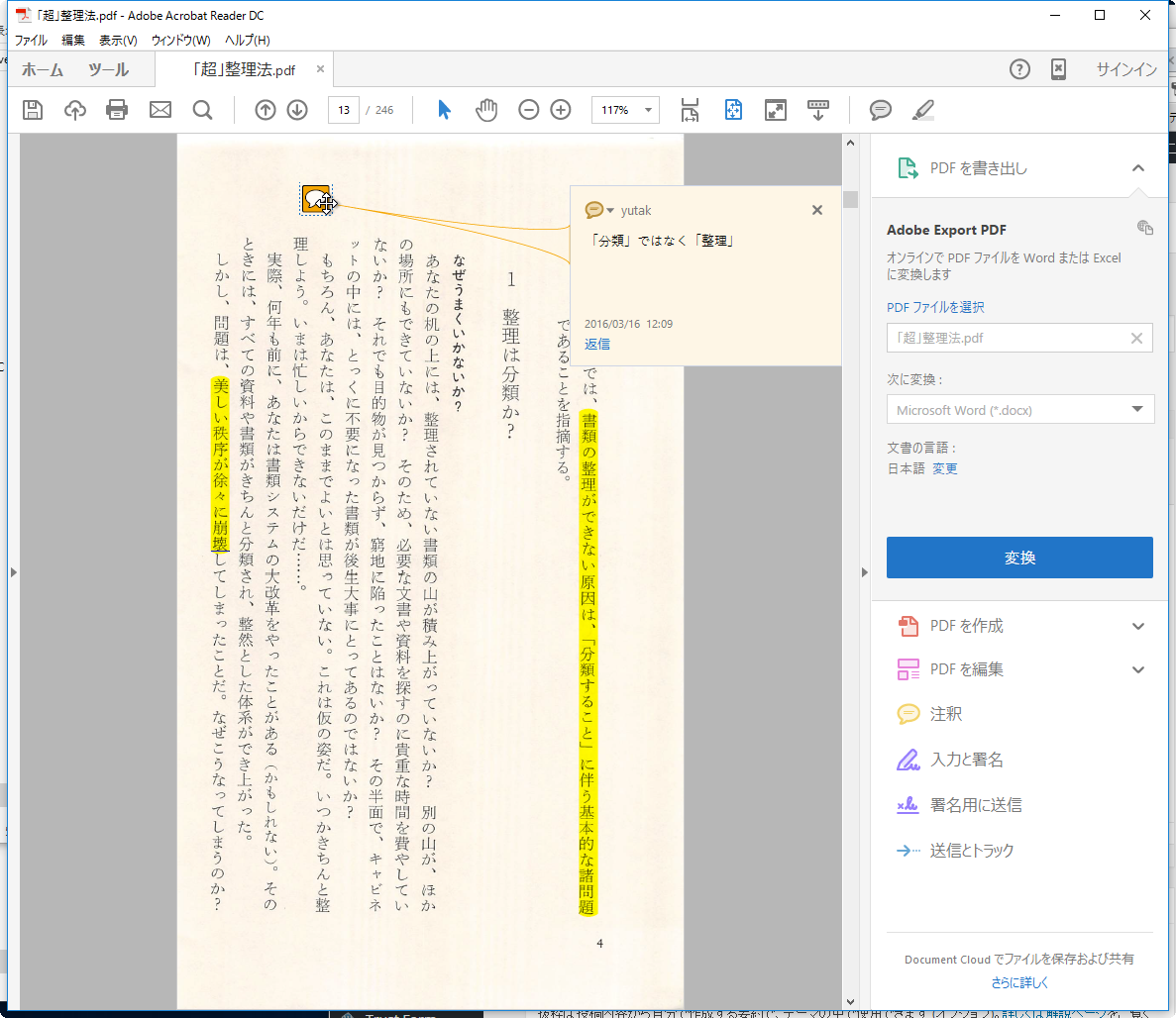
これらは後々に資料として活用する際に、重要なものとなることでしょう。
”自炊”の手順
私の場合、メンドクサイことが苦手なので、あまり細かいことにこだわってはいません。
1、本の裁断
本にもよりますが、多くは無線(アジロ)綴じ製本となっており、中身が表紙でくるまれて、背の部分は特殊糊で固められています。この場合、比較的簡単に手で分解できてしまいます。
カッターで裁断可能な枚数を考慮して紙にして10枚=20ページ単位くらいごとに、手で割いていきます。
スキャンできるように、一枚ずつバラバラにするためには、カッターで糊づけされている部分を裁断します。普通のカッターとカッターマットの組み合わせでもできますが、やはりラクちんなのは裁断機。

ネット上でも評判のカール事務機の裁断機は、やはり使い勝手がとてもいいです。
これで、1枚ずつにバラします。ページ順を間違えないように気を付けて、、、と。
2、ScanSnapでスキャン

3、スキャンの設定
スキャンする枚数としては、50枚=100ページずつ程度がいいようで、スキャンの設定の「読みとりモード」画面で、「継続読み取りを有効にします」にチェックを入れておくことで、ひとつのPDFファイルとして保存させることができます。

また、検索可能なPDFファイルとして保存するには、「ファイル形式」画面で、「検索可能なPDFにします」にチェックをいれておきます。

4、PDF書籍の保管先
私の場合、取り込んだPDFファイルは、OneDriveの配下に自動的に保存されるように設定しています。
これにより、スマートフォンやタブレット、PCで”読書”ができます。
また、この格納先を、「Windows 10のファイルエクスプローラでPDFファイルを全文検索できるように」しておくことで、文章の中身までキーワードで検索できるようになります。
私が学生時代、読んだ書籍について、重要箇所をカードに書き出して保管しておいたものですが、そんな手間をかけずとも個人の知的データベースがいとも簡単に構築できてしまうわけです。
いやぁ、昭和生まれの人間としては、感慨深いものがございます。